Footprints are the visible and machine-readable traces that show where and how AI participated in creating, editing, or deciding something. They consist of multiple patterns that give people context for how results came to be, help teams audit outcomes, and let organizations meet policy and regulatory needs.
Without these, users cannot judge reliability, repeat a result, or hold the system accountable. With a clear trail, users can verify sources, review decisions, and prevent AI laundering where generated work is passed off as fully human.
Modes of use
Generative mode: In creative and exploratory tasks, footprints act as trails that let people branch, replay, or reuse earlier prompts and outputs. They support non-linear exploration in otherwise linear surfaces like chat. Midjourney, for example, shows the full prompt and parameter list with every generation and allows users to send them to the input box in a single click, making it easy to re-try previous runs or pick up a dropped branch.
Verifying mode: In debugging and audit contexts, footprints expose how the AI processed inputs, which sources it used, and what steps it took. They show whether intent was preserved, whether sensitive data was handled correctly, and whether the process meets compliance standards. Replit’s plan-of-action views let developers review which files and lines of code were touched. GitHub Copilot annotates generated code so developers can trace its reasoning. Perplexity attaches citations so users can trace facts back to their origins.
Where they appear
Interface footprints: Badges, inline markers, expandable panels, or annotations in the UI. These make the origin of the generation’s attributes visible to the user in real time.
System footprints: Logs and metadata that capture model version, parameters, safety modes, sources retrieved, approvals, costs, and latency. These matter for admins and auditors more than end users.
Media footprints: Credentials, watermarks, or edit histories that persist when content is exported, copied, or republished. Adobe embeds model and edit details directly into metadata so provenance survives outside the original tool.
Practical use cases
Review logic:GitHub Copilot is capable of annotating code it generated, causing the AI to share its logic openly so the user can trace back and understand how it came up with its code.
Replicating creative steps: Midjourney shows the prompt, references, and parameters used to create every generated image and video, and allows users to search their history by prompt or parameter.
Verifying information:Perplexity includes citations and references with its search summaries so the user and visitors can trace facts and information back to where they originated.
Improving data connections: Intercom's Fin includes reporting on how the agent navigates conversations and references information, including data footprints to help managers improve the performance of knowledge documentation.
Inadvertant footsteps
Not all footprints are intentional. AI-generated content often carries telltale phrases:
Punctuation cues like overuse of em-dashes
Grammatical cues, like the sentence framing “it's not just [blank], it's [blank]”
Visual cues, like the highly-saturated, purple-based color palette commonly produced by code generators
These all can undermine credibility when shared unedited into public spaces. At scale, this “AI garbage” becomes a footprint of its own of AI slop across the web.
AI Garbage content is one form of a footprint making its way across the internet (via the Verge)
Other risks include exposing sensitive metadata, retaining user actions longer than policy allows, or letting footprints be stripped out in ways that obscure provenance. Poorly handled, footprints can become either a liability or a source of misinformation.
Design considerations
Consider footprints at both the interface and system level. Badges, markers, and annotations make a generation‘s history visible, while logs and metadata preserve details for later audit. Both are necessary in many contexts.
Make footprints discoverable and consistent. Use iconography, links, and affordances that direct attention to them in the same way across the product.
Support branching and replay. Let users click a prior footprint to auto-populate a prompt, regenerate an output, or explore a new branch in order to make further generation easy and effortless.
Protect sensitive footprints. Encrypt logs, restrict access, and provide retention controls. Admins need governance tools, and users need assurance that their traces are not misused.
Treat footprints as first-class data. Expose them via API, make them queryable, and integrate them with analytics and compliance systems so users can maintain ownership over their generation history regardless of the tool they are using to access the model.
Store details like parameters used in the generation for easy retrieval via footprints in the UI, and allow users to inset all or some of that generation (including the prompt, parameters, attachments, etc) for a new action.
To let users work backwards from a generation and show which sources the AI used or referenced in its work, use citations.
Examples
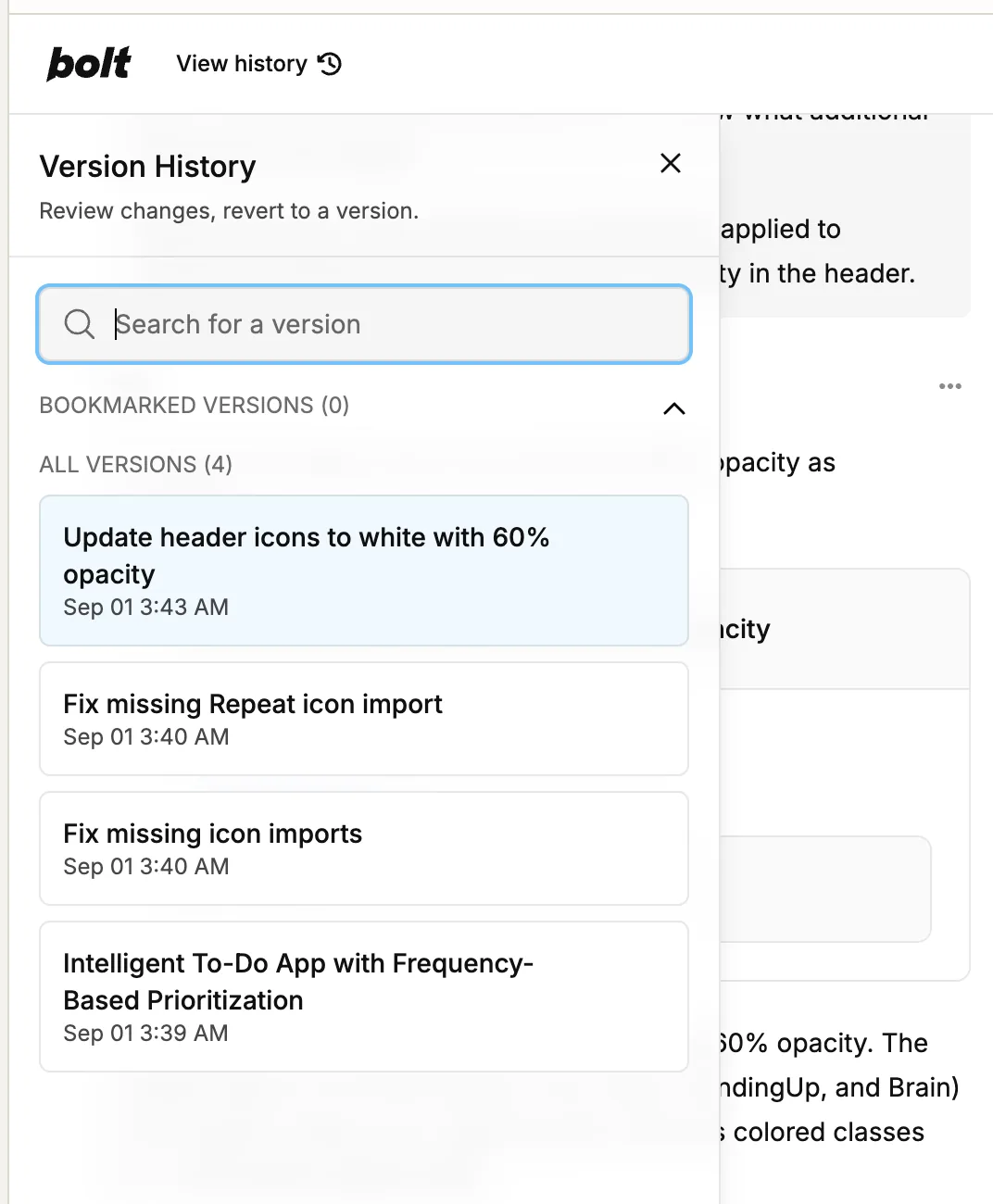
Bolt tracks across iterations of the build. Users can click back through the history to see how the interface evolved
When in logic mode, ChatGPT explains how it processed the task and reached its conclusion, allowing users to surgically identify where logic may have gone awry
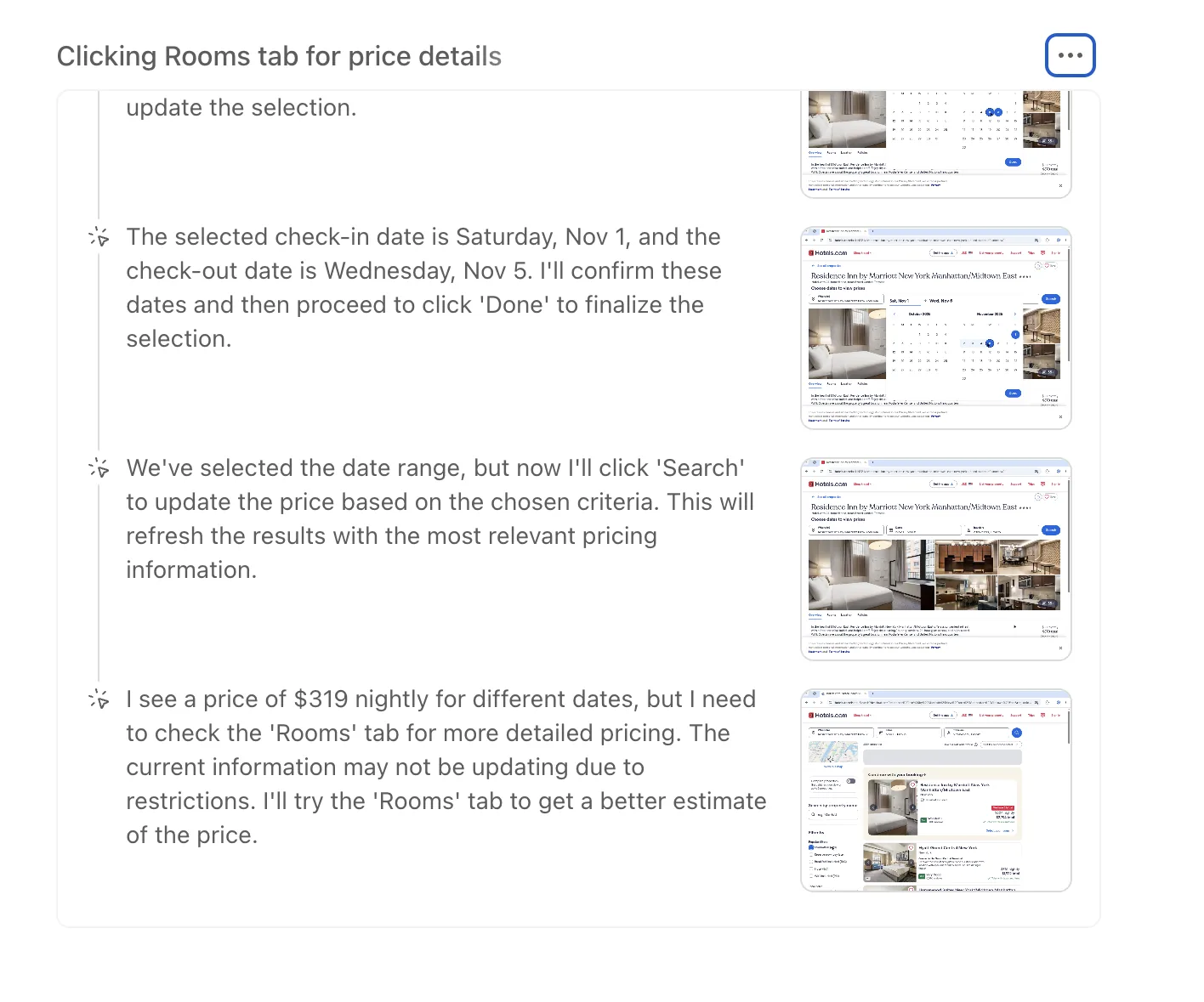
ChatGPT agent mode includes a view on the browser inset that shows all of the logical steps and screenshots the AI walked through to complete a task. Users can also scrub back through the live video to view the steps in real time
FloraFauna’s open layout shows how all blocks are connected, so users can visually track the progress of a string of prompts as the group runs
Adobe Firefly shows the generative history of the most recent variations so users can pull references forward as they iterate
When used in discord, Midjourney’s meta data on any variation links back to the original file. Months after starting a branch, a few clicks can route the user back through the history of their generation