Filters give users the ability to control which sources, tokens, or inputs an AI system should prioritize or avoid. They act as governors on the generation process, shaping the boundaries of what the AI considers before it produces an output. Without filters, AI may surface irrelevant sources, generate unwanted styles, or waste compute on directions that don’t align with user intent.
Filters apply in two primary contexts:
- Source filters: Limit where the AI can draw context from. In search or retrieval systems, this might mean restricting queries to academic sources, documentation, or a particular database. In conversation, it can mean pointing the AI only to recent chats or specific files.
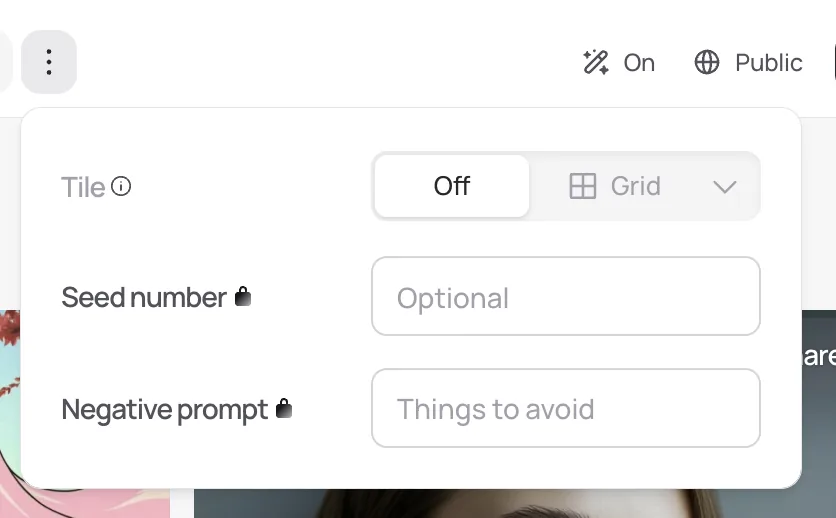
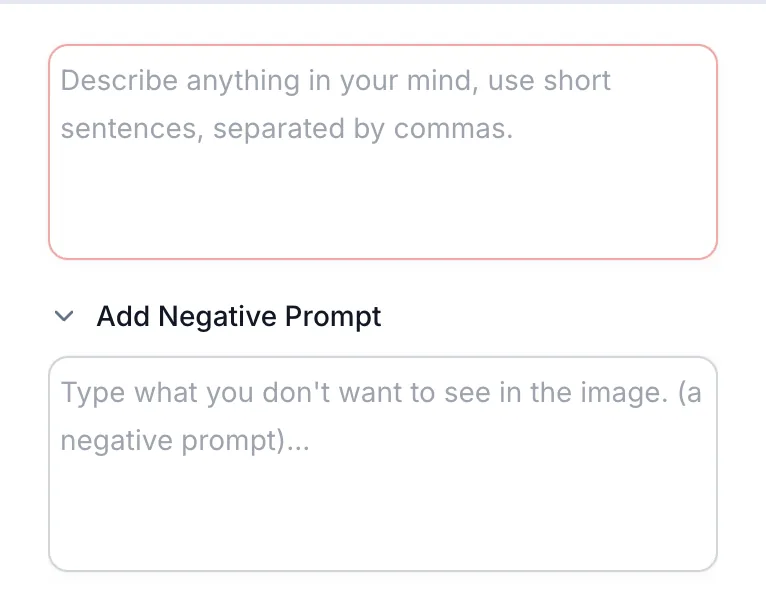
- Token filters: Negative prompting tells the AI to down-weight specific tokens that influence the composition, subject, or styles of the generation. This is most common in image and video tools, where the model might be told “no blur” or “or text.” In writing tools, filters can block certain words or phrases from being used, such as brand-inappropriate terms, jargon, or unwanted topics.
Leakage is possible, and filters do not avoid hallucinations. Combine filters with proactive tuners such as attachments and editable references for the AI to rely on.
Source filtering
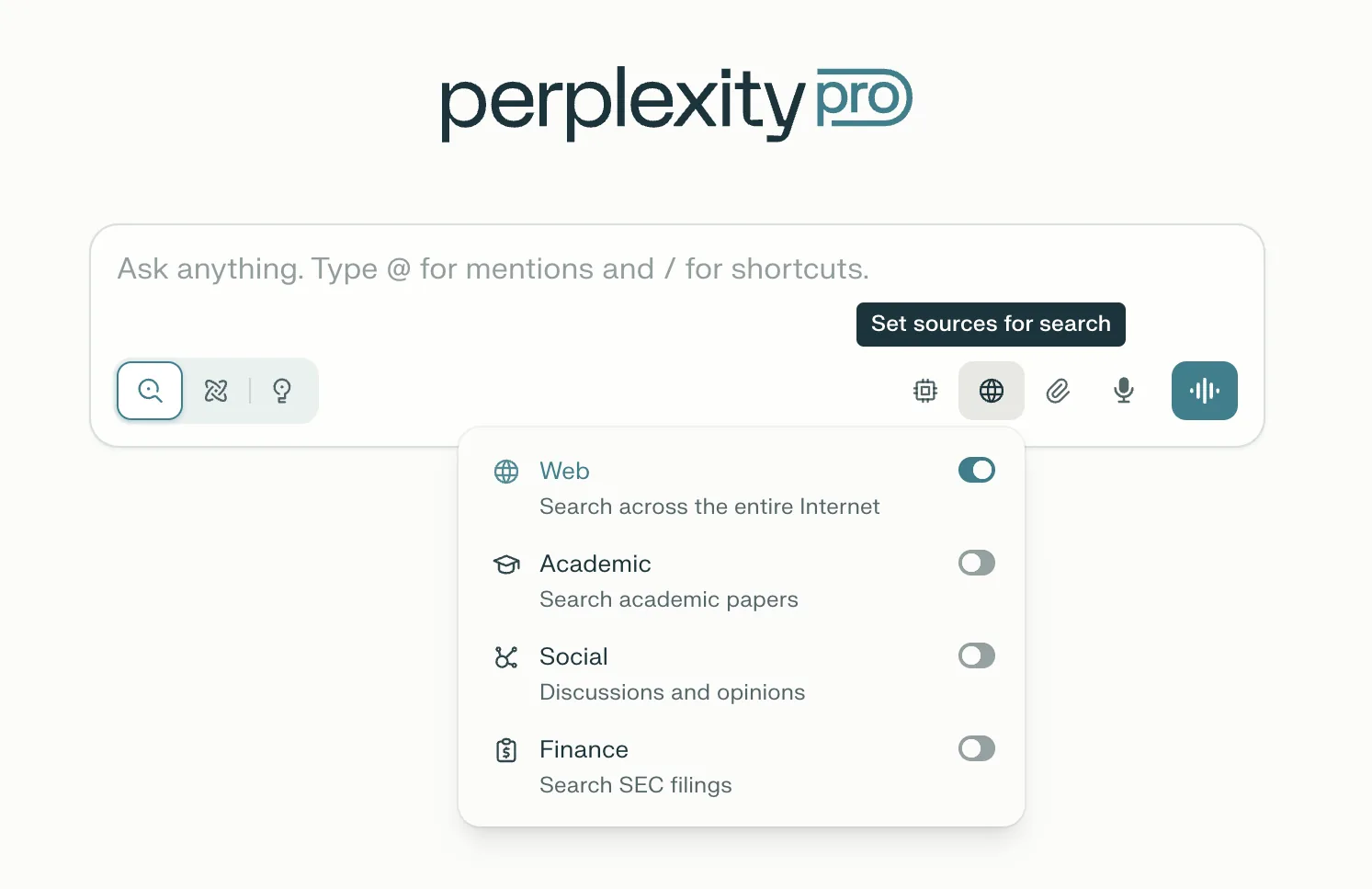
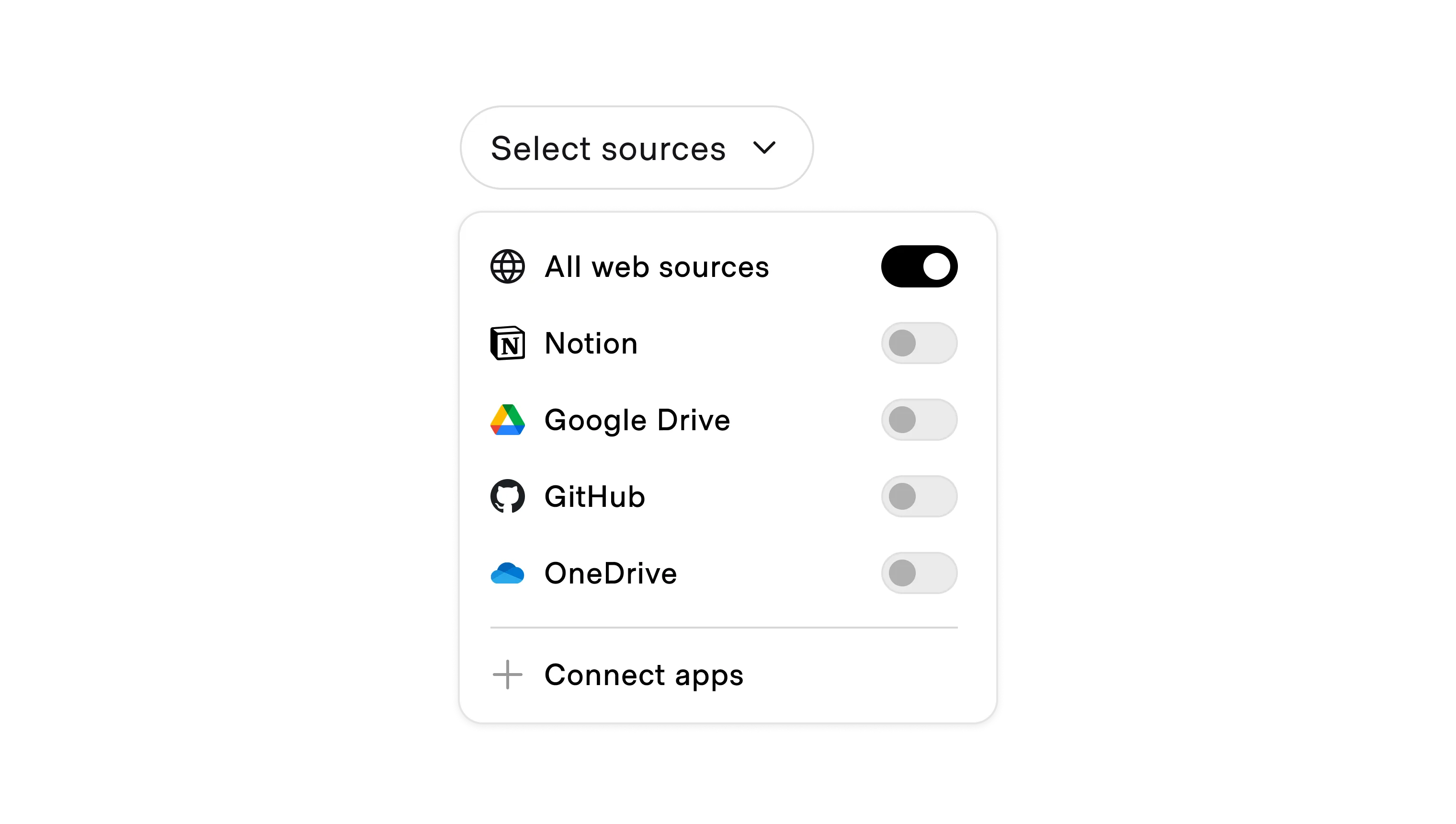
In open-ended contexts, filters help users guide AI to relevant sources. For example:
- Perplexity: Lets users filter results to scholarly sources or exclude Reddit threads.
- Notion: Supports the ability to limit AI queries by team or workspace.
- ChatGPT with browsing: Can be instructed to “search only official documentation” or “ignore blog posts.”
- Enterprise copilots: Allow users to confine retrieval to specific knowledge bases, like internal wikis or Jira tickets.
Token-level filtering
When generating content across modalities, filters are used to prevent unwanted outcomes. For example:
- Stable Diffusion / Midjourney: Support negative prompts like “no blur, no watermark, no text” to suppress undesired tokens and traits.
- LLM generation: Some tools let you block certain words or phrases from ever appearing in the AI’s output. For example, a company might stop the model from using profanity or language that doesn’t fit their brand.
- Code copilots: Can filter out insecure functions or deprecated libraries.