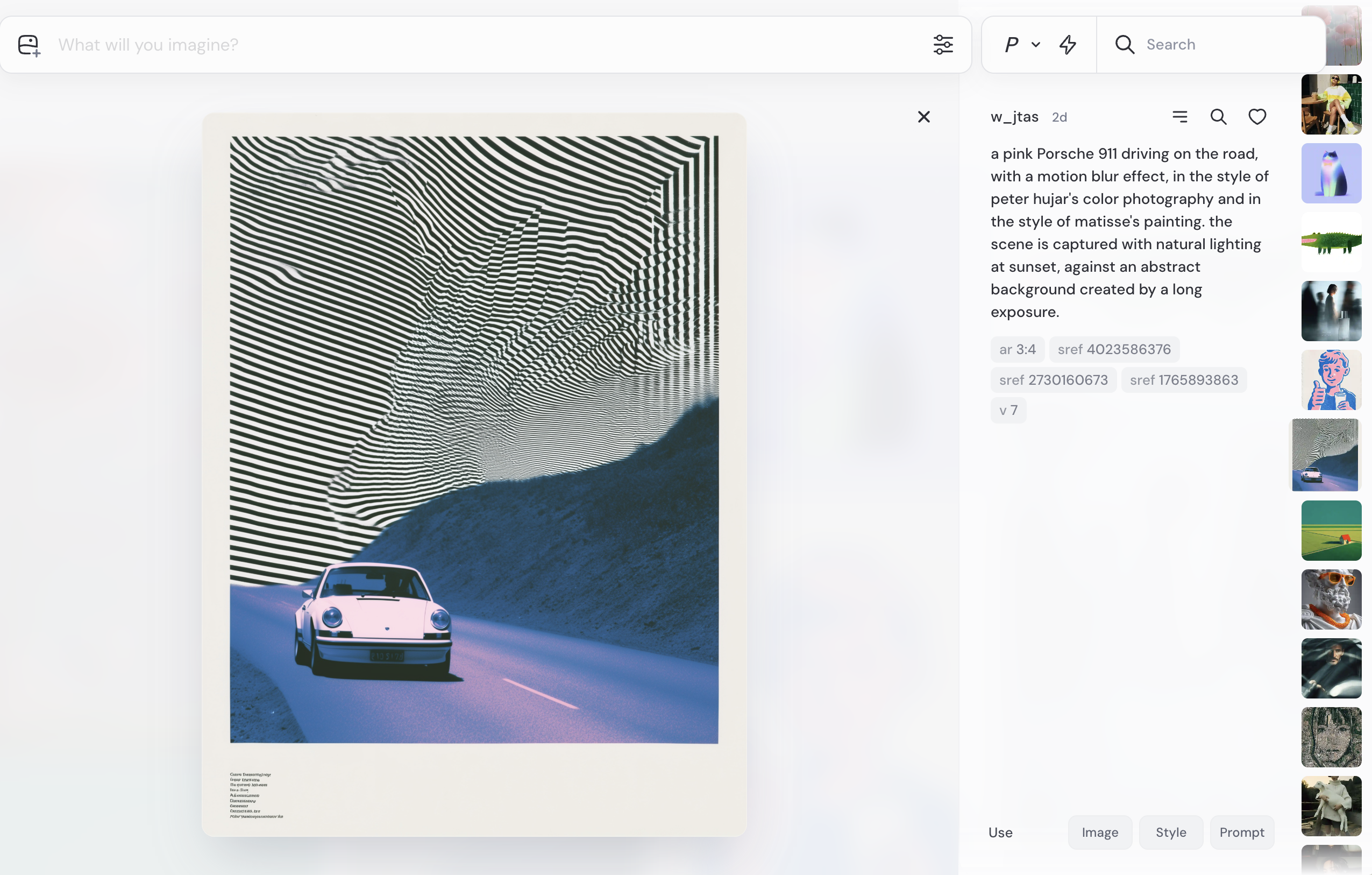
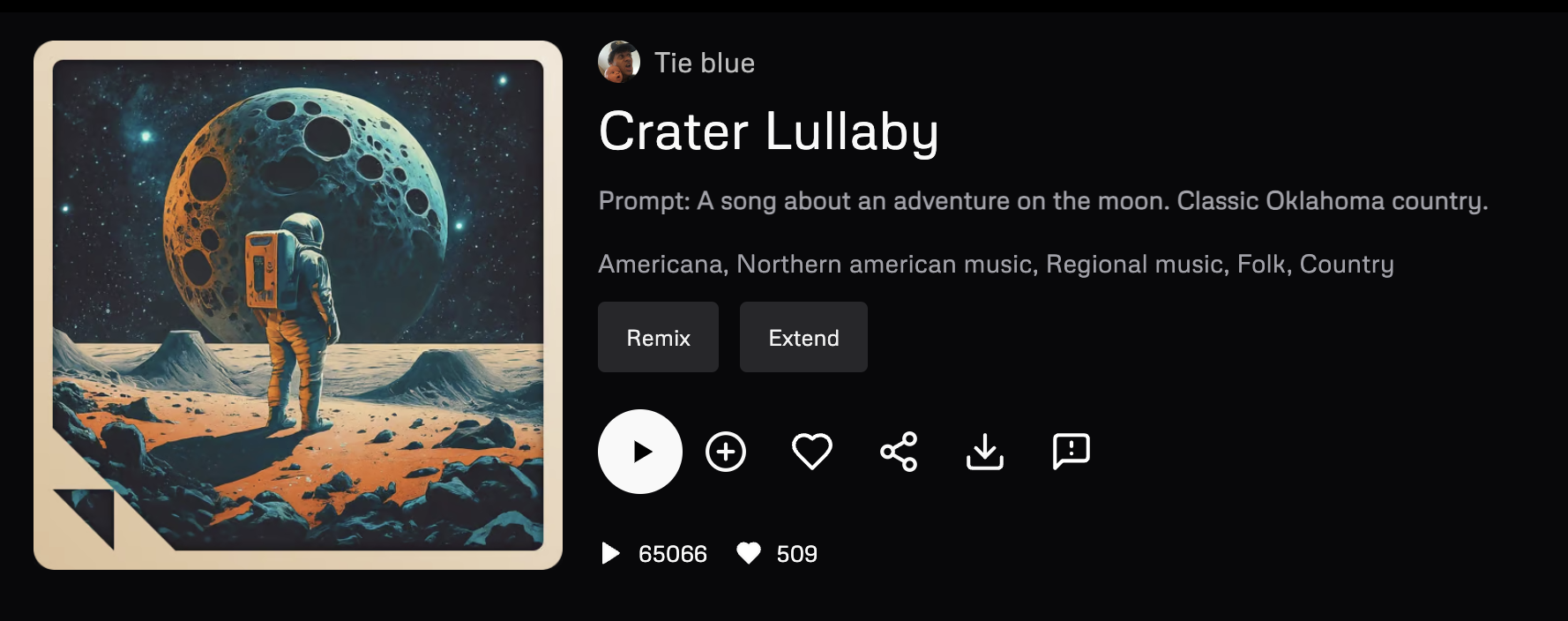
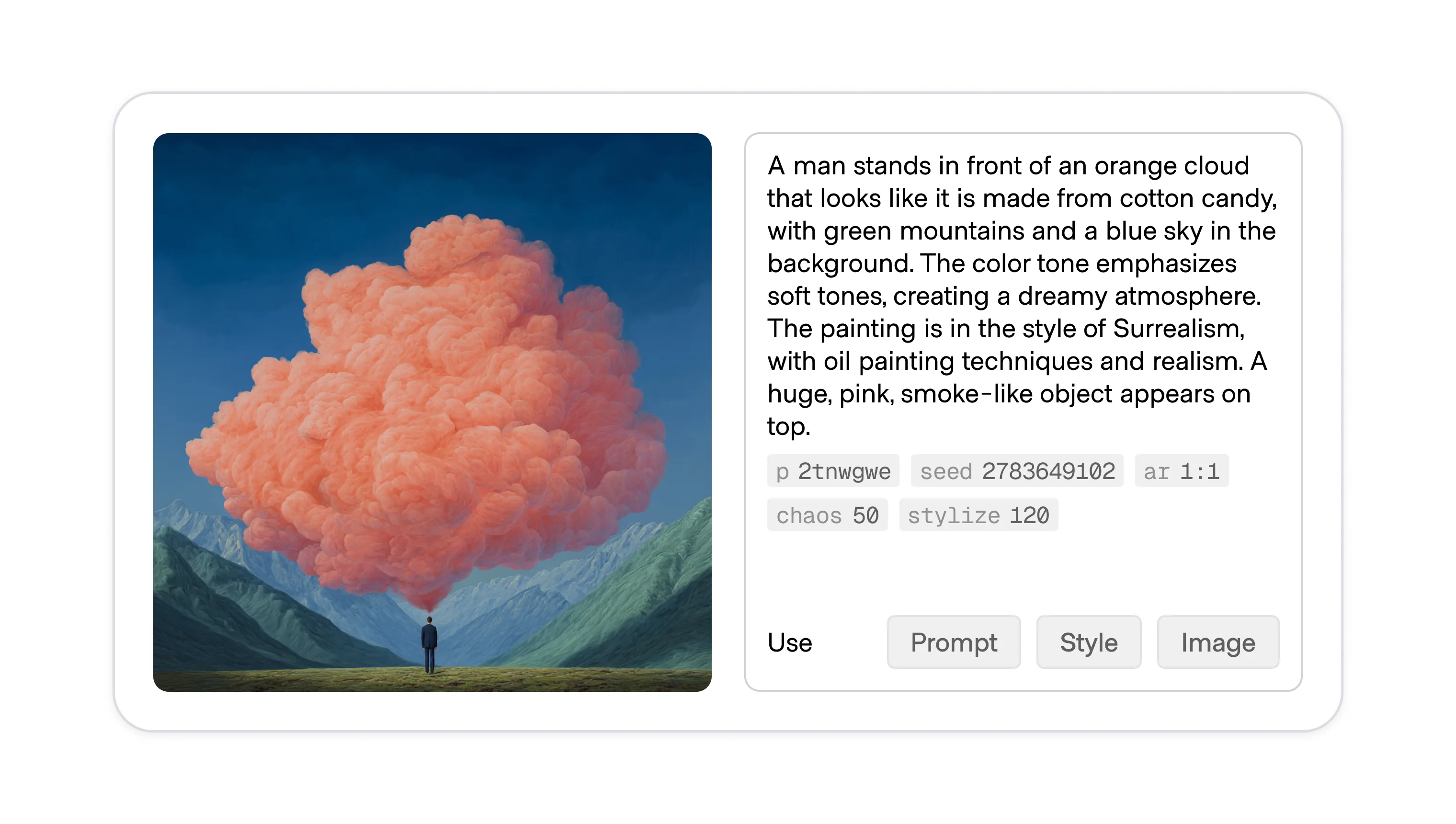
Making prompt details or related details visible alongside an artifact in galleries, feeds, or shared workspaces gives viewers a direct sense of how a result was produced. This helps them learn phrasing, assess originality, and decide whether and what to remix, while making details easily accessible to reuse for additional inputs.
When visible in galleries, prompt details make work legible and reproducible by others. Users can be inspired by prompts created by others, and discover new ways to engage with the model. This reduces the initimidation of getting started for new users and expands creativy as users get more advanced.
Prompt details may appear inline under the artifact, in a side panel on selection, or within an expandable “Details” section. What is included varies: some products show just the raw prompt text, others also include parameters like model name, seed, style tags, or negative prompts. In audio tools, visibility often means surfacing descriptive tags or lyrical snippets. In image tools, it is usually the full text prompt with optional parameters. Choose the depth to expose based on the amount of control and transparency required by the user's experience level and contextual use case.
Consider sharing all or some of these details alongside the generated asset:
In a generative setting, the prompt details can be action triggers in and of themselves, where clicking on each adds it to the input box to be used in the next run. This makes the details interactive and not just informative, and encourages creative exploration.